
Build a Data Dashboard using Airbyte and Streamlit
Uncovering the magic of Python + Airbyte

Hello fellow developers!
Welcome to the Programming and Doodles blog, today, we’re going to build a dynamic data dashboard using Python, Airbyte, and Streamlit.
That means, if you have a dataset hosted somewhere like Google Sheets, and its values frequently change, this data dashboard will not only show you the visualized data (you can customize these graphs) but also update it automatically as the changes happen on the source file (i.e. Google Sheets in this case)

To build that, we’ll use Airbyte, a data integration tool that allows you to easily sync data from various sources (like Google Sheets, databases, APIs, etc.) to your desired destinations (such as data warehouses, like Pinecone in this tutorial)

But that leaves us with a big question— why Airbyte? Well, I had the same question when researching its alternatives only to conclude that it’s the simplest EL tool, with great compatibility for Python and web application tools like Streamlit.
Some fellow developers complain that it’s slow compared to others but in this case, it was not an issue at all, either due to the size of the data set or using Pinecone as the data destination. All in all, it’s decided that if you possess a sample dataset and you want to build a real-time data dashboard with Python, AirByte + Streamlit is the ultimate duo.

You can also view the code on GitHub - Buzzpy / Python Projects / Data Dashboard. The sample data file can be found on - Google Sheets.
Prerequisites
Python 3.9+ installed and ready to use.
Streamlit: We'll use Streamlit to create the dashboard along with the graphs and charts, and you can install it using
pip install streamlitcommand.Pandas for data manipulation.
pip install pandasPinecone library for fetching the data from Pinecone.
pip install pinecone
Setting up data integration on AirByte
The purpose of using Airbyte here is to enable automatic synchronization and data integration in our source file and the destination. The purpose of setting up a destination is to fetch synchronized data for the visualization dashboard. And yes, the purpose of the visualization dashboard is to get to know about your data
Now that the process is clear, we can move on to setting up our data integration, or in proper terminology, “connections“.
Go to cloud.airbyte.com/signup and create an account.
After the account is set, click on “Create your First Connection“

In the next section, select “Set up a new source" and search and select Google Sheets connector.

In the next section, fill the Spreadsheet URL with this sample dataset: https://docs.google.com/spreadsheets/d/1NQtUz4cFTfJssRj87LxkkeqEebvCmXYFwbfSeKwAa3E/edit?usp=sharing. Then click the “Sign in with Google“ button, and sign in to your Google account in which this spreadsheet is held.

Once you get the “Authentication succeeded“ message, click the “Set Up Source“ button.



Next up, you’ll be asked to set up a destination. While AirByte provides various destination connectors, we’ll be using Pinecone due to its easy setup.


Setting up Pinecone
Go to https://login.pinecone.io and create an account.
After the account is set up, click on the Databases tab in your dashboard and create an index.

In the next section, give your index a name and set up its configuration as in the following image. Then click on “Create Index“ at the bottom of the page and your Pinecone index is ready!



Circle back to the Airbyte destination set up and fill out the entries as below:
Chunks: chunks refer to groups of data entries (such as 100-500 rows) that are processed and synced together from your source (Google Sheets) to Pinecone during each sync operation. Let’s set it to 1000 for now.
Embedding: Embedding refers to a vector representation of data. Keep it as “Fake“ for now.
For entries in “Indexing“, use information from your Pinecone index,
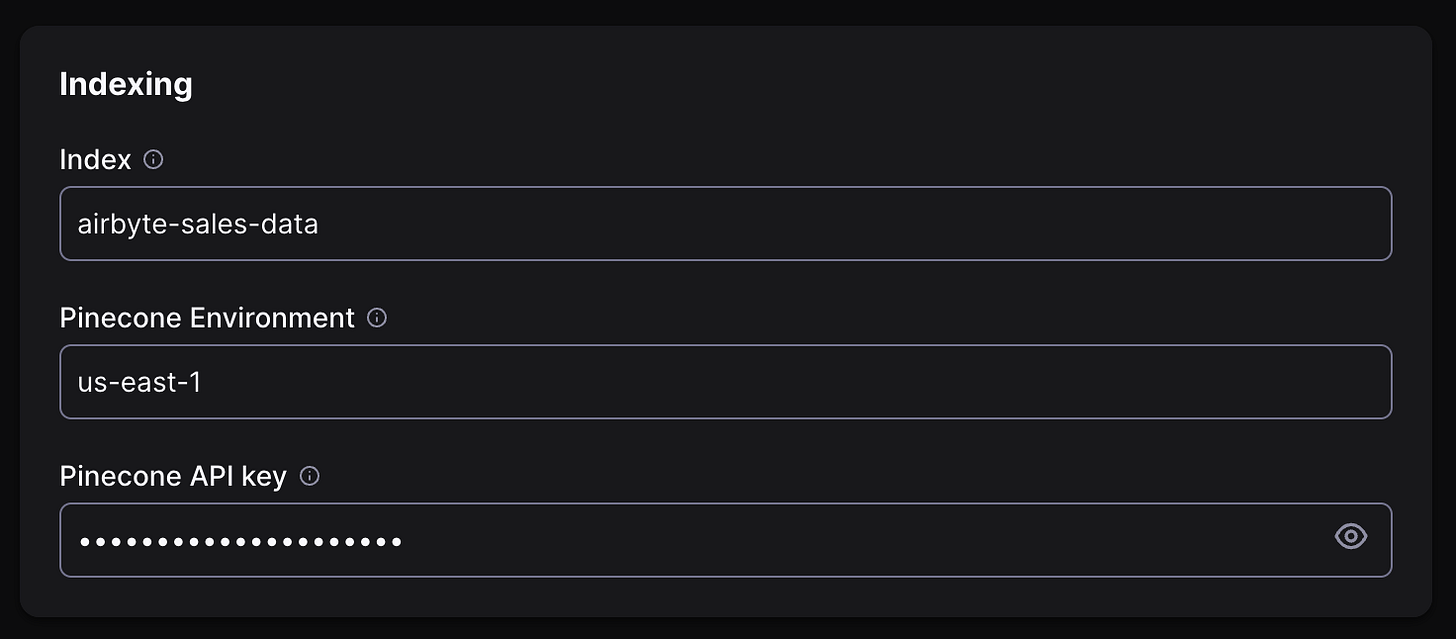
Once all above-required entries are filled out, click on “Set up destination“.
After that, AirByte will fetch the schema of our data source and then you’ll have to select the synchronization model For this application, select the “Replicate Source” option and continue.

Finally, you’ll be directed to the final configuration section. Check if everything’s correct and click on the “Finish & Sync” button at the bottom of the page to sync our dataset.


And that’s it! You have officially set up your data integration with Airbyte!

Writing the code
Our Google Sheets CSV file is integrated and synced with Pinecone at the moment. What we have to do now is write the script for our data dashboard using Python, Streamlit, and MatplotLib.
To start with, let’s import the libraries needed and set up Pinecone authentication. Remember to have your API key ready.
import streamlit as st
import pandas as pd
import time
import numpy as np
import matplotlib.pyplot as plt
from pinecone import Pinecone, ServerlessSpec
import os
# Set your Pinecone API key in environment variables (ensure it's never hardcoded in the code)
os.environ['PINECONE_API_KEY'] = 'gojofjoidgjfd-your-api-key-here'
# Initialize Pinecone instance
pc = Pinecone(api_key=os.environ['PINECONE_API_KEY'])
# Define your index name
index_name = "airbyte-int"Thereafter, we can write a function to fetch the data from Pinecone and then convert it to a dataframe using Pandas.
Inside the same function, we can pre-process the dataset entries for the sake of data visualization.
def fetch_all_data(top_k=1000):
"""
Fetches top k results from the Pinecone index.
And returns a pandas DataFrame.
"""
try:
# Access Pinecone index
index = pc.Index(index_name)
# Query Pinecone for `top_k` results
result = index.query(
vector=np.random.random(1536).tolist(),
top_k=top_k,
include_metadata=True
)
# Extract metadata from matches and return as DataFrame
data = [match['metadata'] for match in result['matches']]
df = pd.DataFrame(data)
# Clean and preprocess data for visualization
df['SALES'] = pd.to_numeric(df['SALES'], errors='coerce')
df['QUANTITYORDERED'] = pd.to_numeric(df['QUANTITYORDERED'], errors='coerce')
df['ORDERDATE'] = pd.to_datetime(df['ORDERDATE'], errors='coerce')
return df
except Exception as e:
st.error(f"Error fetching data from Pinecone: {e}")
return pd.DataFrame() # Return an empty DataFrame if an error occurs
After writing the above function, we can write another function the create graphs for the pre-processed meat. I mean, data.
For the visualization, we’ll use Steamlit’s built-in graphing module.
def display_graphs(df):
# Display raw data table
st.write("Fetched Data:")
st.dataframe(df)
# Total Sales by Product Line
if 'PRODUCTLINE' in df.columns and 'SALES' in df.columns:
product_sales = df.groupby('PRODUCTLINE')['SALES'].sum().sort_values(ascending=False)
st.write("Total Sales by Product Line:")
st.bar_chart(product_sales)
# Quantity Ordered by State
if 'STATE' in df.columns and 'QUANTITYORDERED' in df.columns:
state_quantity = df.groupby('STATE')['QUANTITYORDERED'].sum().sort_values(ascending=False)
st.write("Quantity Ordered by State:")
st.bar_chart(state_quantity)
# Sales over Time
if 'ORDERDATE' in df.columns and 'SALES' in df.columns:
sales_over_time = df.groupby(df['ORDERDATE'].dt.to_period('M'))['SALES'].sum()
st.write("Sales Over Time (Monthly):")
st.line_chart(sales_over_time)
Finally, we can create a Steamlit app UI, using the following code.
# Streamlit App UI
st.title("Real-Time Sales Data Dashboard")
st.write("This dashboard fetches and visualizes real-time sales data from Pinecone.")
# Fetch data automatically on load
with st.spinner("Fetching data from Pinecone..."):
df = fetch_all_data(top_k=1000)
# If data is fetched successfully, display graphs
if not df.empty:
st.success("Data fetched successfully!")
display_graphs(df)
else:
st.error("No data fetched. PleAnd voila! You have built your real-time data dashboard with Steamlit. To run the code, type in the following in your terminal.
streamlit run sales_dashboard.pyYou’ll be automatically directed to http://localhost:8501 in your default browser, where you can see the dashboard we built.
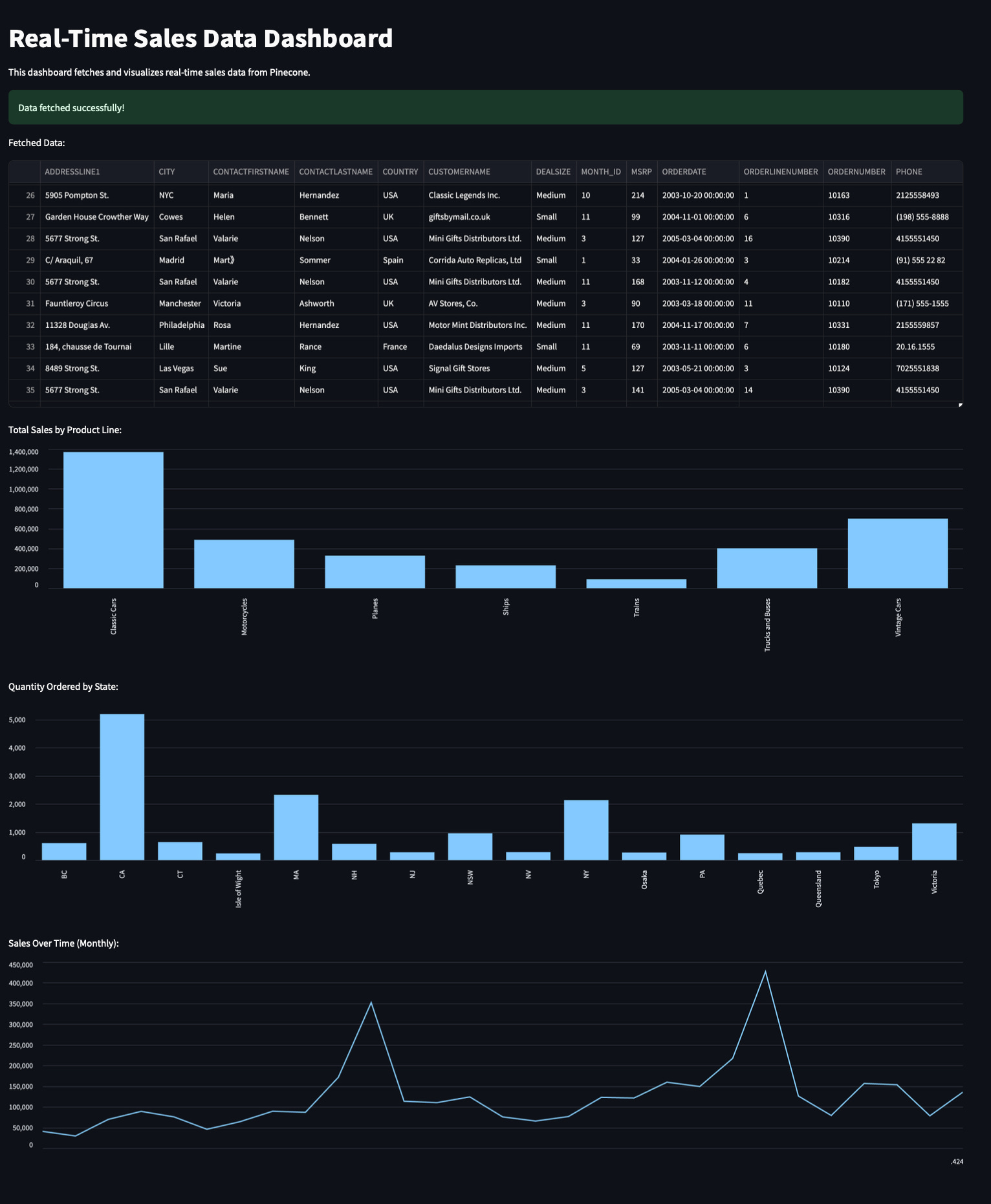
View the full script on GitHub
Feel free to add more graphs, change your source data, or deploy the Streamlit web app.
Wrapping Up
In this tutorial, we built a real-time data dashboard using Airbyte and Streamlit, in Python programming language. The tools we used include: Airbyte for data integration, Google Sheets for hosting the source data, Pinecone for destination of source data, and Streamlit for building the web application and visualization.
Please note that this isn’t the only way to build a data dashboard; there are numerous tools that you can combine together and end up with something similar, better or worse than the one we built. Find out what suits your needs and your skill set before you decide on one option!
The Octavia Octopus design is copyrighted by Airbyte. All rights belong to them.