
Build your own Machine Learning Model using TensorFlow
A tutorial to get hands-on experience with ML

Hello beautiful people! Hope that 2025 is treating you well, even though it’s been buggy for me, so far.
Welcome to the Doodles and Programming blog and today we’re going to build: A sentiment analysis model using TensorFlow + Python.

In this tutorial, we’ll also learn about the basics of Machine Learning with Python, and as mentioned before, we’ll be able to build our own Machine Learning Model with Tensorflow, a Python library. This model will be able to detect the tone/emotion of the input text, by studying and learning from the sample dataset provided.
Prerequisites
All we need is some knowledge of Python (the most basic things, of course), and also, make sure you have Python installed in your system (Python 3.9+ is recommended).
However, if you find it hard to go through this tutorial, don’t worry! Shoot me an email or a message; I’ll get back to you ASAP.
In case you aren’t aware, what is Machine Learning?
In simple terms, Machine Learning (ML) is making the computer learn and make predictions, by studying data and statistics. By studying the provided data, the computer can identify and extract patterns and then make predictions based on them. Identification of Spam Emails, speech recognition, and prediction of traffic are some real-life use cases of Machine Learning.
For a better example, imagine we want to teach a computer to recognize cats in photos. You’d show it lots of pictures of cats and say, "Hey, computer, these are cats!" The computer looks at the pictures and starts to notice patterns – like pointy ears, whiskers, and fur. After seeing enough examples, it can recognize a cat in a new photo it hasn’t seen before.

One such system that we take advantage of every day is email spam filters. The following image shows how it’s done.

Why use Python?
Even though Python Programming Language is not built specifically for ML or Data Science, it’s considered a great programming language for ML due to its adaptability. With hundreds of libraries available for free downloading, anyone can easily build ML models by using a pre-built library without the need to program the complete procedure from scratch.
TensorFlow is one such library built by Google for Machine Learning and Artificial Intelligence. TensorFlow is often used by data scientists, data engineers, and other developers to build Machine Learning models easily, as TensorFlow consists of a variety of machine learning and AI algorithms.
Visit the Official TensorFlow Website
Installation
To install Tensorflow, run the following command in your terminal:
pip install tensorflowAnd to install Pandas and Numpy,
pip install pandas numpyPlease download the sample CSV file from this repository: Github Repository - TensorFlow ML Model
Understanding the data
#1 rule of data analysis and anything that’s built on data: Understand your sample data first.
In this case, the dataset has two columns: Text and the Sentiment. While the ”text” column has a variety of statements made on movies, books, etc, the “sentiment” column shows whether the text is positive, neutral, or negative, using numbers 1, 2, and 0, respectively.
Data Preparation
The next rule of thumb is to clean the duplicates and remove null values in your sample data. But in this case, since the given dataset is fairly small and doesn’t contain duplicates or null values, we can skip the data-cleaning process.

To start building the model, we should gather and prepare the dataset to train the sentiment analysis model. Pandas, a popular library for data analysis and manipulation, can be used for this task.
import pandas as pd
# Load data from CSV
data = pd.read_csv('sentiment.csv')
# Change the path of downloaded CSV File accordingly
# Text data and labels
texts = data['text'].tolist()
labels = data['sentiment'].valuesThe above code converts the CSV file to a data frame, using pandas.read_csv() a function. Next, it assigns the values of the “sentiment” column to a Python list using the tolist() function and creates a Numpy array with the values.
Why use a Numpy array?
As you might already know, Numpy is basically built for data manipulation. Numpy arrays efficiently handle numerical labels for machine learning tasks, which offers flexibility in data organization. That’s why we’re using Numpy in this case.
Processing Text
After preparing sample data, we need to reprocess the Text, which involves Tokenization.
Tokenization is the process of splitting each text sample into individual words or tokens, so that, we can convert the raw text data into a format that can be processed by the model, allowing it to understand and learn from the individual words in the text samples.
Refer to the below image to learn how tokenization works.
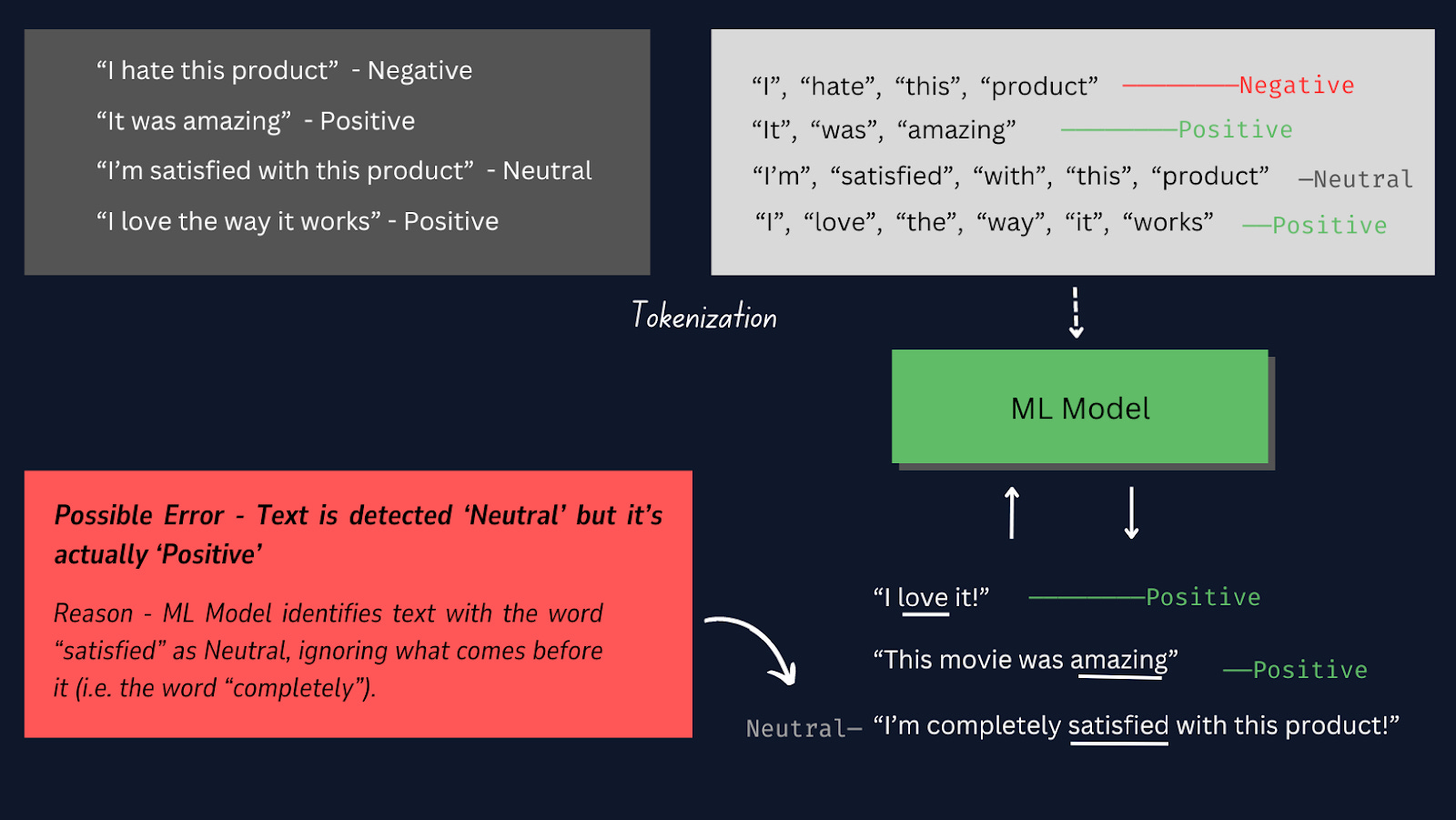
In this project, it’s best to use manual tokenization instead of other pre-built tokenizers as it provides us with more control over the tokenization process, ensures compatibility with specific data formats, and allows for tailored preprocessing steps.
Note: In Manual Tokenization, we write code to split text into words, which is highly customizable according to the needs of the project. However, other methods, such as using the TensorFlow Keras Tokenizer, come with ready-made tools and functions for splitting text automatically, which is easier to implement but less customizable.
Following is the code snippet we can use for tokenization of sample data.
word_index = {}
sequences = []
for text in texts:
words = text.lower().split()
sequence = []
for word in words:
if word not in word_index:
word_index[word] = len(word_index) + 1
sequence.append(word_index[word])
sequences.append(sequence)
In the above code,
word_index: An empty dictionary created to store each unique word in the dataset, along with its value.sequences: An empty list that stores the sequences of numerical representation of words for each text sample.for text in texts: loops through each text sample in the “texts” list (created earlier).words = text.lower().split(): Converts each text sample to lowercase and splits it into individual words, based on whitespace.for word in words: A nested loop that iterates over each word in the “words” list, which contains tokenized words from the current text samples.if word not in word_index: If the word is not currently present in the word_index dictionary, it’s added to it along with a unique index, which is obtained by adding 1 to the current length of the dictionary.sequence. append (word_index[word]): After determining the index of the current word, it’s appended to the “sequence” list. This converts each word in the text sample to its corresponding index based on the “word_index” dictionary.sequence.append(sequence): After all the words in the text sample are converted to numerical indices and stored in the “sequence” list, this list is appended to the “sequences” list.
In summary, the above code tokenizes the text data by converting each word to its numerical representation based on the dictionary word_index, which maps words to unique indices. It creates sequences of numerical representations for each text sample, which can be used as input data for the model.
Model Architecture
The architecture of a certain model is the arrangement of layers, components, and connections that determine how data flows through it. The architecture of the model has a significant impact on the model’s training speed, performance, and generalization ability.
After processing the input data, we can define the architecture of the model as in the below example:
model = tf.keras.Sequential([
tf.keras.layers.Embedding(len(word_index) + 1, 16, input_length=max_length),
tf.keras.layers.LSTM(64),
tf.keras.layers.Dense(3, activation='softmax')
])
In the above code, we use TensorFlow Keras which is a high-level neural networks API built for fast experimenting and prototyping of Deep Learning models, by simplifying the process of constructing and compiling machine learning models.
tf. keras.Sequential(): Defining a sequential model, which is a linear stack of layers. The data flows from the first layer to the last, in order.tf.keras.layers.Embedding(len(word_index) + 1, 16, input_length=max_length): This layer is used for word embedding, which converts words into dense vectors of fixed size. The len(word_index) + 1 specifies the vocabulary size, 16 is the dimensionality of the embedding, and input_length=max_length sets the input length for each sequence.tf.keras.layers.LSTM(64): This layer is a Long Short-Term Memory (LSTM) layer, which is a type of recurrent neural network (RNN). It processes the sequence of word embeddings and can "remember" important patterns or dependencies in the data. It has 64 units, which determine the dimensionality of the output space.tf.keras.layers.Dense(3, activation='softmax'): This is a densely connected layer with 3 units and a softmax activation function. It's the output layer of the model, producing a probability distribution over the three possible classes (assuming a multi-class classification problem).

Compilation
In Machine Learning with TensorFlow, compilation refers to the process of configuring the model for training by specifying three key components— Loss Function, Optimizer, and Metrics.
Loss Function: Measures the error between the model's predictions and the actual targets, helping guide model adjustments.

Optimizer: Adjusts the model's parameters to minimize the loss function, enabling efficient learning.
Metrics: Provides performance evaluation beyond loss, such as accuracy or precision, aiding in model assessment.

The below code can be used to compile the Sentiment Analysis Model:
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
Here,
loss='sparse_categorical_crossentropy': A loss function is generally used for Classification tasks whether the target labels are integers and the output of the model is a probability distribution over multiple classes. It measures the difference between true labels and predictions, aiming to minimize it during training.optimizer='adam': Adam is an optimization algorithm that adapts the learning rate dynamically during training. It’s widely used in practice because of its efficiency, robustness, and effectiveness across a wide range of tasks when compared to other optimizers.metrics = ['accuracy']: Accuracy is a common metric often used to evaluate classification models. It provides a straightforward measure of the model's overall performance on the task, as the percentage of samples for which the model’s predictions match the true labels.

Training the Model
Now that the input data is processed and ready and the model’s architecture is also defined, we can train the model using the model.fit() method.
model.fit(padded_sequences, labels, epochs=15, verbose=1)padded_sequences: The input data for training the model, which consists of sequences of the same dimensions (padding will be discussed later in the tutorial).labels: Target labels corresponding to the input data (i.e. sentiment categories assigned to each text sample)epochs=15: An epoch is one complete pass through the complete training dataset during the training process. Accordingly, in this program, the model iterates over the complete dataset 15 times during the training.
When the number of epochs is increased, it will potentially improve the performance as it learns more complex patterns through the data samples. However, if too many epochs are used, the model may memorize training data leading (which is called “overfitting”) to poor generalization of new data. The time consumed for training will also increase with the increasing number of epochs and vice versa.

verbose=1: This is a parameter for controlling how much output the model’s fit method produces while training. A value of 1 means that progress bars will be displayed in the console as the model trains, 0 means no output, and 2 means one line per epoch. Since it would be good to see the accuracy and loss values and the time taken for each epoch, we’ll set it to 1.
Making Predictions
After compilation and training of the model, it can finally make predictions based on our sample data, simply by using the predict() function. However, we need to enter input data in order to test the model and receive output. To do so, we should input some text statements and then ask the model to predict the sentiment of the input data.
test_texts = ["The price was too high for the quality", "The interface is user-friendly", "I'm satisfied"]
test_sequences = []
for text in test_texts:
words = text.lower().split()
sequence = []
for word in words:
if word in word_index:
sequence.append(word_index[word])
test_sequences.append(sequence)
Here, test_texts stores some input data while the test_sequences list is used to store tokenized test data, which are words split by whitespaces after turning into lowercase. But still, test_sequences will not be able to act as the input data for the model.
The reason is that many deep learning frameworks, including Tensorflow, usually require input data to have a uniform dimension (which means the length of every sequence should be equal), to process batches of data efficiently. To achieve this, you can use techniques like padding, where sequences are extended to match the length of the longest sequences in the dataset, by using a special token like # or 0 (0, in this example).
import numpy as np
padded_test_sequences = []
for sequence in test_sequences:
padded_sequence = sequence[:max_length] + [0] * (max_length - len(sequence))
padded_test_sequences.append(padded_sequence)
# Convert to numpy array
padded_test_sequences = np.array(padded_test_sequences)
In the given code,
padded_test_sequences: An empty list to store the padded sequences that will be used to test the model.for sequence in sequences: Loops through each sequence in the “sequences” list.padded_sequence: Creates a new padded sequence for each sequence, truncating the original sequence to the first max_length elements to ensure consistency. Then, we're padding the sequence with zeros to match the max_length if it's shorter, effectively making all sequences the same length.padded_test_sequences.append(): Add a padded sequence to the list that will be used for testing.padded_sequences = np.array(): Converting the list of padded sequences into a Numpy array.

Now, since the input data is ready to use, the model can finally predict the sentiment of input texts.
predictions = model.predict(padded_test_sequences)
# Print predicted sentiments
for i, text in enumerate(test_texts):
print(f"Text: {text}, Predicted Sentiment: {np.argmax(predictions[i])}")In the above code, the model.predict() method generates predictions for each test sequence, producing an array of predicted probabilities for each sentiment category. Then it iterates through each test_texts element and np.argmax(predictions[i]) returns the index of the highest probability in the predicted probabilities array for the i-th test sample. This index corresponds to the predicted sentiment category with the highest predicted probability for each test sample, which means the best prediction made is extracted and shown as the main output.
Special Notes: np.argmax() is a NumPy function that finds the index of the maximum value in an array. In this context, np.argmax(predictions[i]) helps determine the sentiment category with the highest predicted probability for each test sample.
The Program is now ready to run. After compiling and training the model, the Machine Learning Model will print out its predictions as for the input data.

In the model’s output, we can see the values as “Accuracy” and “Loss” for each Epoch. As mentioned before, Accuracy is the percentage of correct predictions out of total predictions. The higher accuracy is better. If the accuracy is 1.0, which means 100%, it means that the model made correct predictions in all the instances. Similarly, 0.5 means the model made correct predictions half the time, 0.25 means correct prediction quarter of the time, and so on.
Loss, on the other hand, shows how badly the model’s predictions match the true values. The lesser loss value means a better model with less number of errors, with the value 0 being the perfect loss value as that means no errors are made.
However, we can’t determine the overall accuracy and loss of the model with the above data shown for each Epoch. To do so, we may evaluate the model using the evaluate() method and print its Accuracy and Loss.
evaluation = model.evaluate(padded_sequences, labels, verbose=0)
# Extract loss and accuracy
loss = evaluation[0]
accuracy = evaluation[1]
# Print loss and accuracy
print("Loss:", loss)
print("Accuracy:", accuracy)Output:
Loss: 0.6483516097068787
Accuracy: 0.7058823704719543Accordingly, in this model, the Loss value is 0.6483 which means the Model may have made some errors. The accuracy of the model is about 70%, which means the predictions made by the model are correct more than half of the time. Overall, this model can be considered a “good” model; however, please note that the “good” loss and accuracy values highly depend on the type of model, the size of the dataset, and the purpose of a certain Machine Learning Model.
And yes, we can and should improve the above metrics of the model by fine-tunning processes and better sample datasets. However, for the sake of this tutorial, let’s stop from here. If you’d like a second part on this tutorial, please do let me know!
Summary
In this tutorial, we built a TensorFlow Machine Learning Model with the ability to predict the sentiment of a certain text, after analyzing the sample dataset.
The Full Code and Sample CSV File can be downloaded and seen in the GitHub Repository - GitHub - Buzzpy/Tensorflow-ML-Model
And until next time, happy coding!
A quick note:
"pip install tensorflow"
People who write instructionals that involve python on Linux need to realize that a number of distros these days lock down the system python to avoid software conflicts. So "pip install" anything won't work. One has to use a python virtual environment or pipx. This should be noted in any instructional especially for the more naive user (like me - bitten often.)